|
这几天隔壁有群友问了我一个非常专业的问题:多曝工艺是什么?它是如何跨过光刻机的极限分辨率实现更小制程的工艺?
好问题,毕竟半导体工艺的问题专业是真的专业,真不是普通人能理解的,网上很多理解都是错的。 想要了解多曝工艺的问题,首先得了解这个知识点的前置知识,因此今天内容分三段,第一、光刻设备分辨率是怎么来的?第二、晶体管的特征尺寸以及等效工艺的命名方式?第三、多曝工艺是什么,一共有哪几种多曝工艺??? 本人水平有限,如有错误请各位大佬指正,本文尽可能通俗易懂,但是部分内容还是涉及非常专业的半导体知识,看不懂的评论区讨论,说不定有大佬亲自上阵解释。
一、光刻机的极限分辨率 光刻机到今天我相信大家都知道它是干嘛的。
说人话,光刻机的作用就是把掩膜板的图形,按比例精确投影到硅片上,完成集成电路工艺图形化转移的第一步。 请注意,它只是投影,它没有刻的过程,刻的过程是另外一种设备完成的,那就是刻蚀机。 因此光刻机本质上和单反相机是一样的,只是精细度非常之变态。之所以会走投影技术路线道理也很简单,因为它适合大规模量产。一片晶圆经过光刻工艺之后,就完成了千上万个芯片的曝光工作,效率非常高,远远超过其他技术路线,高效率意味着更低的成本,所以到现在为止别看其他技术路线叫的响,比如纳米压印,但是实际产线上根本就没啥大规模应用,主流依然是投影这个路线,甚至往后的很多年以内,投影技术路线的地位不可撼动。 以ASML NXT 1980Di的官方数据,它的产能是每小时275片,前置条件是单片晶圆曝光96个区域,同时每平方厘米能给30焦耳的能量。 目前没有一个其他的技术路线,包括电子束,纳米压印之类的能做到这样的量产规模,更别提其他技术路线,那些都只是实验室玩玩的,离FAB厂量产差十万八千里。 懂一点的光学知识的人都知道,由于光的衍射效应,在极度微缩的情况下,光的投影不再是一个理想的几何图形,而是有一定大小的光斑,这个光斑专业词叫“艾里光斑”。 当两个物点过于靠近,其像斑重叠在一起,就可能分辨不出是两个物点的像,即光学系统中存在着极限分辨率,对于集成电路工艺而言,那就是光刻机的极限分辨率。 悬挂在ASML的办公室上有个神奇的公式,叫瑞利判据公式(Rayleigh criterion) 瑞利判据是波长和数值孔径的表达式,因此光刻机的工程师们会用瑞利判据去定义一个成像系统的分辨能力。 它长这样。
公式中的CD,如果在集成电路工艺中就指晶体管的特征尺寸,代表着极限分辨率下的最小线宽。λ则代表光刻机使用光源的波长;NA(Numerical Aperture)则是光学器件的数值孔径,描述了它们能够收集光的角度范围;K1包含了光学临近效应,包括光刻胶成分或者光刻机温度的控制等,是众多其他影响因子的汇总,这和使用方芯片制造公司的“手艺”有密切关系,不同的公司,这门“手艺”水平差距巨大。 数学好的同学一眼就看出来,想要得到更小尺寸的晶体管,就必须要有更小的光刻机CD,想要得到更小的CD,无非从这几个参数入手。 1、缩小λ即光刻机的波长;2、增大NA数值孔径;3、缩小K1的影响力(提高使用者“手艺”水平)。 因此早期的光刻机为了更小的CD,把资源都集中在如何缩小λ光刻机的波长方面。 于是光刻机的波长一路降低,从早期的高压汞灯G线的436nm,I线的365nm,再到准分子激光器DUV KrF的248nm再到ArF的193nm,F2的157nm,再到193nm浸没式等效出134nm,到现在出现了极紫外EUV 的13.5nm。而NA数值孔径和光刻机投影系统的设计有密切关系,如今也变得越来越复杂。 对于ASML这样的光刻机设备公司而言,K1是客户端的事没有办法把控,能做的就在公式中的λ光刻机波长和投影系统的数值孔径NA这两个参数上做文章,从而不断挑战技术高峰,把光刻机的分辨率推向极致。 目前最先进的EUV是ASML的 NXE 3x00系列,再过几年会有高NA版本的EUV出现叫EXE 5x00系列,其中NXE的NA=0.33,而EXE系列则是NA=0.55,甚至规划中还有更大NA=0.75,并且这东西卖到几亿欧一台。
之所以ASML不惜代价,投入巨额资金搞出高NA的EXE光刻机系列,主要是为了5nm以下工艺中,避免使用多曝工艺而增加额外的成本。 因此光刻机的极限分辨率就和晶体管的最小尺寸息息相关。比如一台12英寸的干式193nm光刻机,最小只能做到55nm工艺,再往下就不行了,因此这台光刻机适用范围是90-55nm工艺;而一台KrF的248nm,更适合做0.13um的工艺,因此它更适合在8英寸线上用。 但是请注意,这并不绝对!敲黑板,讲一个99%人都不知道的知识点。 一个芯片制程过程,其实类似盖高楼大厦,其中M0和M1,这最底下的两层,因为需要的分辨率最小,因此需要最先进的光刻机来完成曝光工艺,而之上的金属层并需要,甚至用线宽很大的光刻机也能完成这项工作,因此就有类似i线光源的的12英寸光刻机,看起来非常魔幻,12英寸工艺上居然用i线的12英寸光刻机哦!!!
上图框出来的位置大致就是M0和M1 所以在一个12英寸光刻工艺中,实际上是高,中,低不同类型的光刻机配合完成整个芯片的曝光工作,最先进的光刻机只负责最细线宽处的曝光工作。 这里再插一个小故事,尼康曾经推出过S635i这样的193nm的浸没式光刻机,但是号称是“5nm光刻机”,很多人不明白,怎么193nm的浸没式还能干到5nm?那ASML的EUV光刻机岂不是要吃灰了?河哥岂不是要连夜改简历,投简历了? 其实就是玩了文字游戏。本质是这台S635i设备是整个5nm光刻工艺中的一部分,而非S635i能实现最小分辨率5nm的光刻工艺,635i可能只是负责上层的金属部分曝光工作罢了。 好钢用在刀刃上,因此一台光刻机根据它自身实际性能参数,尽可能物尽其用,用它做最适合的工艺。 理解上面这些内容之后,我们继续讲更深层的东西。 二、晶体管的实际特征尺寸和工艺命名 我们常说的180nm,90nm,45nm,甚至16nm,7nm,3nm稍微懂行的人可能知道,是指这个FAB工厂能实现的最小工艺线宽,如果在芯片说明书上标明,那就指这颗芯片是由何种工艺实现的,是7nm?还是3nm? 所谓的90nm,45nm,实际是指晶体管的栅极长度,专业词叫Gate Length。
偶尔也有工程师会讨论Channel Length也就是沟道长度,它们的关系是 Channel Length=Gate Length-2x(Diffusion Length)。 在早期,工艺和晶体管的实际尺寸是一一对应的,比如一颗芯片是用0.35um工艺制造的,那它晶体管的实际大小就是0.35um。 再次敲黑板!但是这一切在45nm-28nm工艺附近开始出现巨大的变化。 原因很简单,Gate Length太短,会出现“短沟道效应”,简单理解成水龙总是关不紧,或者日总那样的老男人时不时会出现尿不尽,漏尿的情况。 这是非常麻烦的事情,这意味这集成电路工艺无法再往下推进,或者说摩尔定律逼近接近极限了。
为此一方面工程师们想尽一切办法去微缩最小尺寸,另外一个角度想尽一切办法,找到更好的栅极材料,来控制晶体管不断微缩后出现的各种麻烦问题。 再举一个非常经典的案例。 以28nm工艺节点为例,这一代工艺有多个版本,有HKMG版本(高K金属栅极),也有Poly版本(多晶硅氮氧栅极),都是28nm,显然它们的工艺性能还是有显著差别的。 敲黑板,再讲一个95%人都不知道的知识点。P.P.A !!! 懂行的小伙伴都知道,P.P.A是衡量一道工艺,一颗芯片的关键指标。它意思是性能(Performance),功耗(Power),以及面积尺寸(Area),是这三个英文字母的缩写。 说白了,任何工艺/芯片都被希望有着更好的性能,更低的功耗,以及更小的面积尺寸,但是通常这就像“男人不可能三角”一样,有钱,长的帅,用情专一,这样的男人是不可能存在的。 但是工程师们还是努力在P.P.A.之间突破,并且寻找新的平衡点,为兼顾性能和成本,这才是工程师们的真正KPI,以及掉头发的原因。 这里再做一个假设。 假如有个新一代工艺,相比28nm工艺,它让晶体管体积小了30%,功耗降低了25%,晶体管密度提高了50%,性能提升了40%,但是实际Gate Length,并没有改变多少。 注意:这不是真实数据,只是打个比方。 请问它算几nm工艺?还是28nm吗?显然不是。 要不我们就叫它等效14nm工艺吧,于是14nm就这么来的。 可以所到现在28nm以下的工艺,几乎都是等效出来,而FinFET工艺开始,全是等效,并且工程师们不再用Gate Length,而用half -pitch(半间距)来分辨它们。 我再举个通俗例子,奥迪车尾上你看不到多少排量,它总是用35 TFSI 或者45 TFSI 之类的标称。 请问,一辆 奥迪A6L 45 TFSI 的涡轮增压发动机实际相当于自然吸气多少升排量?
哦,大概相当于自然吸气的2.5L排量的发动机。 大概,大概,大概,重要的说三遍。 我相信举这个例子,各位就明白什么叫等效的概念。 再举一个例子,比如早期AMD因为频率上打不过intel,因此就想了个PR标称法,比如速龙3000+CPU你觉得它对标intel哪款CPU?看名字像奔腾3.0对吧,但是实际3000+主频只有2.2G,但是它看起来像3.0G的! 这一切看起来似乎像玩文字游戏,这种等效叫法确实也造成一定的宣传口径不统一。例如明明台积电的N7工艺和英特尔10nm工艺各方面都差不多,但是一个就是叫7nm,一个就是叫10nm,相比之下用台积电N7工艺制造的AMD Zen系列CPU看起来就比英特尔10nm工艺制造的CPU更强些,英特尔在宣传方面吃了个亏,一个10nm,一个7nm,你选谁?明显AMD的7nmCPU宣传上占了很大便宜。 所以到现在intel也发现在宣传上有点弄不过这群老6,干脆在之后的命名规则上,直接叫“intel 4”,经典的打不过就加入。 同样台积也没有14nm工艺,它一直叫16nm。 记忆中三星甚至有一版叫18nm的工艺的特别存在(这点不确定,年代久远有点记不住了),其实都是等效intel的14nm,自己给自己取个等效的名字罢了。 今天各位看官能记住并理解工艺P.P.A.以及等效工艺概念,只能说你学到了,总之不亏,最终赢麻!
三、多重曝光工艺
最核心的问题来了。
什么叫多重曝光工艺?为什么会有这样的工艺出现? 早些年ASML的193nm 浸没式光刻机,极限情况下能实现大约22nm左右工艺的单次曝光。(反复提醒,实际gate length 并不是22nm) 那么在EUV没有出现之前,是怎么实现22nm以下节点的比如14nm,7nm,之类的呢?
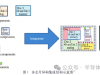
于是当年intel投入重金搞出了多重曝光工艺这样的神技。 多曝技术有好几种,主要是LELE,LFLE,以及SADP/SAQP三种。 LELE,其实是Lith-Etch-Lith-Etch的缩写,意思是光刻-刻蚀-光刻-刻蚀。 它是把原来一层光刻图形被拆分到两个或多个掩膜上,实现了图像密度的叠加。
图片来自知乎
这样就实现了比光刻机极限分辨率更小的图形。
但是请注意,这个提升的更小特征尺寸非常有限,不可能出现什么45nm一步跨到22,甚至14nm的情况。 同理LFLE,它是Ltiho-Freeze-Ltiho-Etch, 光刻-固化-光刻-刻蚀。 它是LELE的工艺的一个变种版本,本质差不多,但是可以省一道刻蚀的工序,降低一些制造成本和风险。 SADP叫SELF ALIGNED DOUBLE PATTERNING 自对准双重图形化,英特尔曾经还搞出过SAQP四重曝光技术,原理差不多。 SADP是一种取代传统LELE的双重图形化工艺,通过侧墙自对准工艺的双重图形化方案,即通过一次光刻和刻蚀工艺形成轴心图形,然后在侧壁通过原子层淀积和刻蚀工艺形成侧墙图形,去除轴心层(即牺牲层),形成了pitch减半的侧墙硬掩模图形。
https://zhuanlan.zhihu.com/p/387004183知乎上有更全面的解释。 英特尔曾经在10nm之后的7nm,搞出了SAQP,四重曝光,并且沉迷这个技术。 它通过DUV深紫外线技术加上SAQP四重曝光技术对M0/M1连续进行多次的曝光处理,最终让金属的中心距从双重曝光(SADP)的40nm提升到20nm。
但是实际上效果不大,工艺太复杂,良率不高,导致产能上不去,成本下不来,不如台积,三星他们在7nm直接导入EUV来的这么痛快。
不同曝光技术的区别,分别是LELE,LFLE,SADP,SAQP 讲到这里给大家再总结一下,不管那种曝光技术,都是为了在有限的光刻机分辨率下实现更小的特征尺寸,其中SAQP效果最好,SADP其次,LELE和LFLE差不多。 但是无论如何都不可能实现,用28nm光刻机做出7nm的工艺。 这就像一个高考模拟考只有三本水平的学生,可以通过靠前突击,努力学习,实现三本到二本,甚至一本的跨越,但是你说他一定能考上清华北大?实在是太难了,无他,物理极限摆着。 以上就是今天科普内容,欢迎大家继续提问。总之各位看完不亏,最终赢麻! 最后放一个群友今天编的神仙段子。 有个小工程师拿着一片wafer在SH湖边走,走着走着,不小心wafer掉湖里了,于是SH湖神出现了,还拿着三片wafer他问,小工程师啊,这里有三片wafer,一片是7nm,一片是5nm,还有一片是3nm制程的,请问哪片是你的呀,小工程师诚实地说:7nm那片是我的,请还给我。 |