|
学习对于边缘智能设备适应不同的应用场景和用户非常重要。目前训练神经网络的技术需要在计算和存储单元之间移动大量数据,这阻碍了在边缘设备上实现学习。 清华大学吴华强团队开发了一种全集成记忆电阻芯片,提高了学习能力,降低了能耗。STELLAR架构中的方案,包括其学习算法、硬件实现和并行电导调谐方案,是通过使用忆阻器交叉棒阵列促进片上学习的通用方法,而不考虑忆阻器器件的类型。在这项研究中执行的任务包括运动控制、图像分类和语音识别。相关研究以“Edge learning using a fully integrated neuro-inspired memristor chip“发表在“Science”期刊上。
图1所示。利用神经启发记忆电阻芯片进行边缘学习。
(A)人类大脑学习能力提高的例证。通过预先获得关于老狗和兔子的知识,只需要几个新的输入,就可以快速实现对新样本(即新狗)和新类(即猫)的学习。(B)基于忆阻器的神经启发计算芯片的设计考虑和未来应用。该芯片专为完全片上学习而设计,将所有必要的模块与忆阻器阵列集成在一起。它为边缘人工智能设备配备了学习能力,使它们能够快速适应新的场景。
人类的学习能力在智力增长和快速适应未知场景(图1A)或动态变化的环境中起着至关重要的作用。边缘人工智能(AI)应用也需要具有这种学习能力的硬件,以使相关设备能够适应新的场景或用户习惯(1)。然而,深度神经网络(DNN)训练(2、3)通常使用基于von Neumann计算架构和高精度数字计算范式的传统硬件实现(4)。处理器芯片和片外主存储器之间广泛的数据移动会产生大量的能量消耗,并且占整个训练过程的大部分延迟(5,6)。因此,尽管云计算平台可以处理这种高能耗的训练(4,7),它们的高能耗阻碍了在功率有限的边缘计算平台上实现学习(1)。相比之下,基于忆阻器的神经启发计算通过其颠覆性的内存计算架构和模拟计算范式消除了这种广泛的数据移动(6,8 - 10)。忆阻器交叉棒阵列利用欧姆定律和基尔霍夫定律,可以在一个时间步内存储模拟突触权值,并在一个时间步内并行进行原位向量矩阵乘法运算。集成多个忆阻器交叉棒阵列和互补金属氧化物半导体(CMOS)电路的神经启发计算芯片可以轻松实现DNN推理(11-14),并且具有很大的潜力,可以完全处理片上学习,而无需任何片外存储器的帮助(15-17)。基于记忆电阻器的神经启发计算提供了大量的能源效率提高,使这种范式有望开发未来的芯片,使低功耗学习设备成为可能。
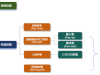
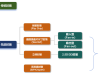
图2所示。用于片上学习的忆阻器结构设计。 (A)忆阻芯片中使用的恒星架构示意图。恒星算法具有基于符号的权值更新计算和权值更新阶段误差符号计算的可重构阈值。(B和C)在MNIST数据集上使用STELLAR和传统BP算法的分类精度(B)和权重更新能耗(C)的仿真比较。(B)和(C)显示了使用BP算法时不同写入变化的结果以及STELLAR学习方法中不同阈值的结果。柱形和误差柱分别表示10次重复实验结果的平均值和标准差。(B)中的虚线表示BP在不考虑忆阻器写入变化的情况下获得的平均精度。(D)差分电导对(左)和1T1R(中)和2T2R(右)配置的权重表示。(E)循环-并联电导调谐方案示意图。红色和蓝色矩形分别代表每个差分对中的正极和负极忆阻器单元。向上和向下的箭头分别表示相关忆阻器单元上的SET和RESET操作。 为了以可观的能效、面积效率和准确性支持片上学习,我们提出了STELLAR架构(图2A)。STELLAR架构利用了忆阻器器件的双向模拟开关行为(32)。在权重更新阶段,只需要根据输入、输出和误差的符号来计算权重更新方向。此外,该体系结构预先定义了一个阈值,在计算错误符号时过滤掉小的错误,避免过于敏感和不必要的更新,对学习算法的收敛起着至关重要的作用。通过省略这些小的更新,恒星更新方案下基于忆阻器的梯度向量可以更接近传统的BP梯度向量,以适应实际设备的非理想因素(如设备电导的不对称调谐)。详细的分析和仿真请参见材料和方法第2节(器件非对称交换下的STELLAR更新方案)。该阈值是硬件可重构的,以适应各种学习任务。恒星架构的算法细节可以在材料和方法第1节(恒星架构的算法)中找到。根据权值更新的方向,一个相应的相同的SET或RESET脉冲被施加到忆阻器单元。该方案避免了复杂的精确权值更新计算和验证过程的编写以及复杂的外围电路设计,实现了硬件的节能。 通过在修改后的美国国家标准与技术研究院(MNIST)数据集上的模拟,将STELLAR架构的学习性能与传统方法进行了比较(33)。在这里,在学习过程开始之前,第二层的所有忆阻器都被设置为随机电导状态。图2B显示了在不同阈值下,传统BP方法在没有和具有不同写入变化(1%和3%,以忆阻器器件全电导窗口的百分比给出)的学习精度与所提出方法的学习精度的比较。模拟细节可以在材料和方法第3节(STELLAR与传统BP算法的比较)中找到。适当选择阈值可以提高收敛性和学习精度(图S1A)。极小的阈值会导致过于频繁的权重更新和网络的振荡状态,而过大的阈值会导致权重更新不足。不同方法的能耗对比如图2C所示。尽管保持了几乎相同的精度,但由于大幅减少了精确的权重更新计算和写入验证开销,STELLAR架构的能耗比传统BP方法低了两个数量级。
图3所示。用于片上学习的忆阻芯片。 (A)忆阻芯片结构概述。(B)芯片的光学显微镜图像,其中几个关键部件被标记。(C)透射电子显微镜(TEM)显示2T2R细胞的横截面图像。2T2R单元中的晶体管共用一个源端。插图:忆阻器器件的透射电镜横截面图像。(D)使用MNIST数据集的片外训练权值获得的每个类别的片上分类精度,柱状图和误差柱状图分别显示了五次推理迭代获得的精度的平均值和标准差。标准差范围为0.07 ~ 0.27。(E)权重转移后48天内分类精度的变化,每个点表示5个推理结果的平均精度。插图:体重转移48天后,每一类准确率的平均变化。插图中的标准差范围为0.1至0.32。(F)在MNIST数据集的片上学习任务中,每个epoch包含60,000次迭代,在三个学习epoch中分类精度的变化。(G)片上学习过程中记忆电阻芯片的能量击穿。 图3A显示了拟议的恒星架构的整体电路实现。该忆阻芯片由控制器组成,用于配置;一个2T2R忆阻器阵列(1568 × 100),一个1T1R忆阻器阵列[100 × 20];参见材料和方法第5节(基于1T1R忆阻器阵列的重量配置);用于计算和编程的BL、WL和SL驱动程序;低成本模数转换器(adc);具有记忆电阻功能的片上学习模块(即,误差循环减法器和权重更新逻辑);输入和输出缓冲区。第一层忆阻器阵列采用2T2R配置,以减少在如此大的阵列中出现的红外下降问题,第二层忆阻器阵列采用1T1R配置,以支持更灵活的原位重量调谐。控制器对输入级选择信号进行解码,并将输出组态信号提供给其他电路模块,使芯片切换到不同的工作级[参见资料和方法第6节(忆阻芯片电路设计)和图S5]。分辨率可调adc (ra - adc)具有可配置的分辨率并支持灵活的阈值(11)。误差计算由减法器完成,由计数器实现。权重更新逻辑确定权重更新方向和电导调整操作。 所制芯片的显微照片如图3B所示。芯片面积击穿如图S6B所示。该忆阻器器件采用TiN/HfOx/TaOy/TiN材料堆叠,制作工艺与标准CMOS工艺兼容[参见材料与方法第7节(忆阻芯片的制作)和图S6A]。因此,忆阻器可以方便地与复杂的CMOS电路集成,以产生优异的良率(几乎100%的所有160,000个电池)。图3C中的透射电子显微镜(TEM)横截面图像显示了忆阻器单元与CMOS电路的集成。所制备的忆阻器具有均匀和可重复的双向模拟开关,具有相同的脉冲序列(图S6D)。总共约160,000个片上忆阻器单元可以统一编程为32种电导状态,最大、最小和平均成功率分别为99.98、99.69和99.90%[参见材料和方法第8节(忆阻器器件的测量)和图S6C]。 片上推理首先用于MNIST手写数字分类。权值在片外训练,然后作为忆阻电导转移到芯片上[参见材料和方法第9节(片外训练和片内推断)]。每个类别(0 ~ 9)的测量分类精度如图3D所示;平均准确率为95.8%。还评估了电池电导波动对芯片精度的影响(图3E)。我们监测了48天的精度,没有观察到明显的精度下降。我们还演示了用忆阻芯片进行实时手写数字识别(见电影S3)。 为了验证基于784-100-10多层感知器(MLP)的片上学习能力,进一步演示了片上学习任务MNIST图像分类。第一层的权值在片外训练,然后以忆阻电导的形式传递到芯片上。第二层的忆阻器首先被编程到高阻状态(HRS),然后使用STELLAR方案更新。所有的数据处理和信号控制过程都在芯片上执行。经过三个epoch的片上学习,训练集和测试集的分类准确率分别从8.6和8.4%提高到94.9和92.3%(图3F)。然后,我们用硬件测量结果评估了片上学习的能耗[参见材料和方法第11节(能耗基准)]。我们还评估了基于数字加速器的系统(36)在同一MLP网络的一次训练迭代中的能耗。片上学习过程中忆阻芯片的能量击穿如图3G所示。通过优化ADC设计可以进一步降低能耗(37-39)。 总结与展望团队开发了一种全集成记忆电阻芯片,提高了学习能力,降低了能耗。STELLAR架构中的方案,包括其学习算法、硬件实现和并行电导调谐方案,是通过使用忆阻器交叉棒阵列促进片上学习的通用方法,而不考虑忆阻器器件的类型。团队展示了新样本和新类在各种任务中的改进学习,包括运动控制,图像分类和语音识别,这表明STELLAR架构适应了设备的非理想性,并为记忆电阻芯片配备了改进的学习能力,以适应新的场景。随着基于先进制造技术的进一步电路工程(41),恒星架构可以使片上学习记忆电阻芯片的能源效率比数字加速器高75倍(36)。更多细节可以在材料和方法第18节(基于忆阻器的学习芯片的能效估计)中看到。这项研究是迈向未来具有高能效和广泛学习能力的芯片的重要一步。希望研究结果能够加速未来智能边缘设备的发展,以适应不同的应用场景和用户。 文献链接Edge learning using a fully integrated neuro-inspired memristor chiphttps://www.science.org/doi/10.1126/science.ade3483
|